Рассмотренный выше алгоритм сглаживания при помощи Leaky Bucket обладает рядом существенных недостатков, среди которых необходимо выделить, как это ни странно, постоянную скорость исходящей нагрузки даже при заполненном буфере. Такая особенность функционирования приводит к тому, что трафик VBR реального времени и чуствительный к задержкам, помещенный в очередь Leaky Bucket для сглаживания, может провести в ней существенное, относительно RTT, время. Факт возможного возникновения такой суще-задержки, вкупе с тем, что зачастую рассматриваемый трафик не обязательно должен быть сглаженным, для того чтобы соответствовать заявленному профилю, наталкивает на мысль о том, ч.то, в принципе, сглаживание при помощи Leaky Bucket может внести отрицательный вклад в параметры функционирования сети и предоставляемых услуг.
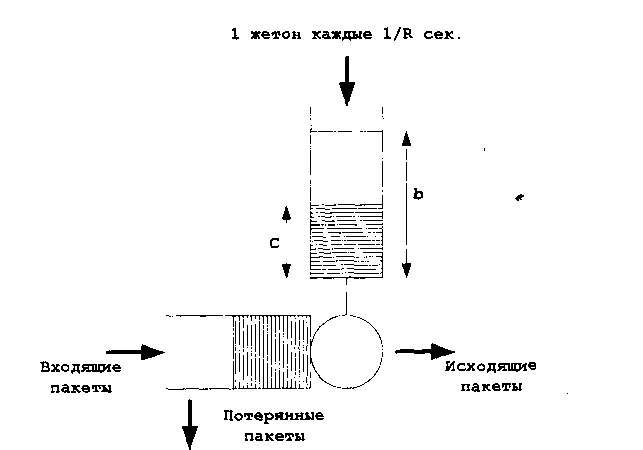
Реализация сглаживания на основе алгоритма Token Bucket по сравнению с Leaky Bucket является более гибкой и справляется с недостатками последнего, но при этом также имеет слабые места. Рассмотрим этот тип сглаживания подробнее. Как было показано ранее, Token Bucket позволяет применять какие-либо действия (сброс или маркировка) только лишь к пакетам, которые не соответствуют заявленному профилю, при этом пакеты, соответствующие профилю, проходят через Token Bucket без какой-либо дополнительной задержки, связанной е ограниченной интенсивностью исходящей нагрузки. Метакод алгоритма и его схема представлены на рис. 2.28 и 2.29.
Предположим, что интенсивность поступления жетонов меньше интенсивности поступления пакетов, т.е. через некоторое количество времени поступающие пакеты будут вынуждены ожидать в буфере генерации жетона, т.е. интенсивность на выходе Token Bucket станет равной интенсивности поступления жетонов. Таким образом, очевидно, что интенсивность исходящего потока для рассматриваемого алгоритма сглаживания не является постоянной, как в случае Leaky Bucket, т.е. пачечность сохраняется, в чем и заключается его недостаток. Однако отметим, что этот недостаток нельзя назвать существенным, т.к. трафик, содержащийся в пачке, соответствует заданному профилю, а высокий коэффициент пачечности, возможно, будет понижен при статистическом мультиплексировании. Отметим, что рассмотренный алгоритм применяется как в архитектуре IntServ, так и DiffServ.

Рис. 2.28. Метакод алгоритма Token Bucket: режим сглаживания
На рис. 2.30 представлено функционирование алгоритма Token Bucket в режиме «сглаживания». Как видно из рисунка, как и для режима «маркировки или сброса», для данного режима дополнительно определяется функция поведения неконформной нагрузки ^'(0, разность межту которой и скоростью обслуживания г определяет количество нагрузки, которое необходимо сгладить. В [Cruz91 -1 j представлено выражение для подсчета количества времени, необходимого для сглаживания, определенного как параметр «максимальная задержка при сглаживании» (Maximum Shaping Delay, далее - MSD), на рис. 2.30 - это значение разности tt- t0\
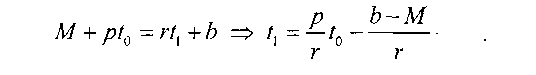
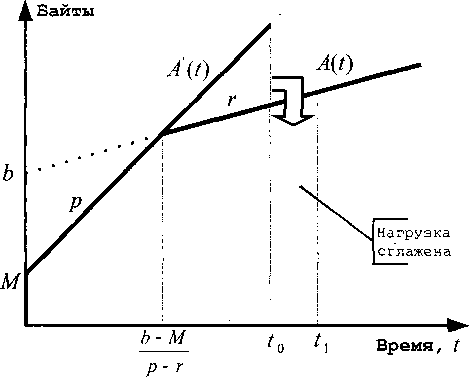
Рис. 2.30. Функционирование алгоритма Token Bucket: режим «сглаживания» Далее необходимо также упомянуть еще один интересный режим функционирования, являющийся частным случаем «сглаживания» - это «сглаживание: параметризация размером буфера» (Buffer Sizing, далее - BF). Главное отличие данной модели от предыдущих заключается в том, что они не предполагали возможность переполнения буфера данных. Предположим, что количество пакетов, находящихся в буфере данных, приблизилось к его размеру, который обозначим через BF, при этом существует определенное количество нагрузки, которая должна быть сглажена. Обратим внимание на рис. 2.31. На основе значения BF мы имеем возможность [Parekh92] рассчитать значение момента времени гькогда лимит буферного пространства для сглаживаемой нагрузки будет исчерпан:
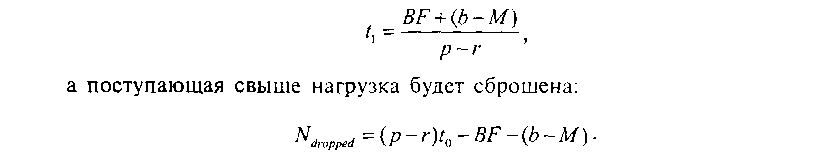
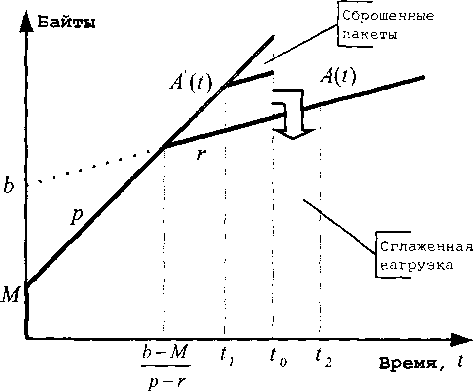
Рис. 2.31. Функционирование алгоритма Token Bucket: режим «сглаживание: параметризация размером буфера»
⇐Сглаживание профиля трафика | Управление трафиком и качество обслужевания в сети | Совместная реализация leaky bucket и token bucket⇒