for (i=2; i< myParagraphStyles.length; i++){
ix = styleApplied.search(myParagraphStyles[i].name); Если стиль не найден (т. е. позиция, найденная методом search, равна -1), то удаляем его и учитываем это в счетчике:
if (ix = -1) {
myParagraphStyles[i].remove(); i-}
}
Последнее обстоятельство необходимо для корректной работы скрипта. По окончании цикла счетчик (i) увеличится на 1, и мы перейдем от первого стиля ко второму. Представьте себе, что первый же существующий в публикации стиль был удален: тогда следующий за ним стиль (второй по счету) займет его место в списке и станет первым, третий - вторым и т. д. по всей цепочке (рис. 6.2). Таким образом, произойдет смещение стилей, и вместо второго перейдем сразу же к третьему стилю (он занял место второго). Чтобы избежать этого, нужно либо компенсировать приращение счетчика, что мы и сделали - либо (кому-то оно покажется даже проще) - начинать проверку с последнего стиля в публикации (for (i=allStyles.length-1; i>=2; i-))
Поскольку нумерация идет с начала, удаление объектов с конца к нарушению нумерации не приведет.
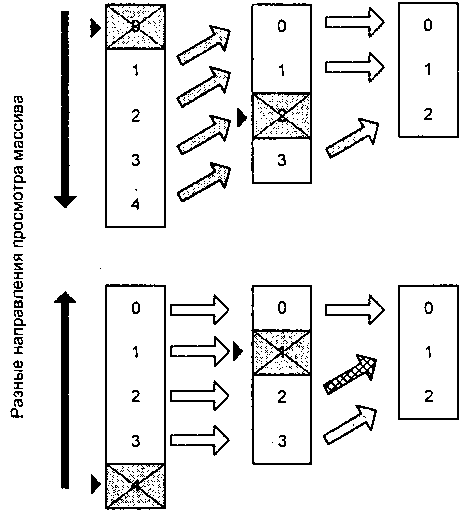
Рис. 6.2. Различия ме>кду двумя вариантами просмотра массива Перечеркнутые элементы- удаляемые, а серыми стрелками показаны смещающиеся элементы массива (у них происходит смена индексов). Предположим, что удаляется первый элемент массива. Видно, что в случае традиционного подхода (проход начинается с начала массива, верхний рисунок) это приводит к изменению индексов у всех остальных элементов массива; если же используется противоположное направление просмотра (нижний рисунок), то никакого смещения не происходит.
Следующим, допустим, удаляется третий элемент. Как видно изу рисунков, картина повторяется: на верхнем четвертый элемент снова меняет свой индекс, на нижнем же для уже пройденных элементов тоже изменится индекс, но для нас это уже не играет никакого значения, поскольку они уже пройдены и больше обрабатываться не будут (обозначены штриховкой), а вот следующий, важный для нас (с индексом 0), свой индекс снова не меняет- это нам и нужно (текущий элемент обозначен черным треугольником).
6.5. Супермегаметла для публикации
На данный момент мы уже обладаем достаточными знаниями для того, чтобы написать скрипт, удаляющий все лишние объекты, в один универсальный суперскрипт.
Лишними будем считать:
пустые фреймы;
пустые абзацы (в которых нет ни одного символа, а также имеющие только пробелы или табуляторы);
неиспользуемые стили;
неиспользуемые образцы цвета (swatches);
объекты, расположенные полностью на монтажном столе.
Таким образом, по своей функциональности скрипт будет являться, по современному, этакой супермегаметлой (листинг 6.9).
| Листинг 6.9. Удаление лишних объектов
myDocument = арр.activeDocument;
myAllItems = арр.activeDocument.allPageltems;
myParagraphStyles =app.activeDocument.paragraphStyles ;
// Параметры поиска:
// для пустых фреймов searchString_l = "/[a-Za-Я]/"